Written by Alma Strakova
As a part of the Digital Humanities minor programme at Leiden University that I have recently graduated from, we were tasked with outlining and executing a final project involving both our newly acquired digital skills, as well as our humanities research knowledge. We had to outline a research question within any field of the humanities and showcase how our digital skills can be useful in conducting research within the field.
Since I was simultaneously working on the ScotPP corpus project while also participating in my minor classes, I thought that it would be fun to challenge myself in combining my final project for my Digital Humanities minor with my work on the Scottish pauper petitions. Furthermore, I thought that it would be a challenge to bring the data of the ScotPP corpus to a general audience, explaining the historical importance of these letters and why they are of value to research being conducted today.
Outlining the project
The first challenge I encountered in working on this project was deciding what exactly I wanted to do with the data I had available. I could have created a project regarding language development, looking into particular aspects of language use present in the letters. However, the lack of normalized spelling in the letters would have made this difficult.
So, I decided to look more into the contents of the letters, to see if I could work with the petitions themselves as my main source of data. I thought that it would be interesting to look into the reasons mentioned in the letters by the paupers as basis for wanting to be admitted onto the Poor’s Roll. Thus, I decided to look for the main reasons mentioned in the letters for petitioning.
After working with the data, I realised that I did not want to just conduct research that could be presented in an article – I wanted to make an interactive platform through which people could learn more about the letters and be educated on the history of petitioning in Scotland. So, I decided to make a simple game in Python, for which the basis would be taken from my own gathered data from the letters regarding the reasons for petitioning. I came up with the idea for a simulation game which allows the player to write their own petition by completing a quiz. The game, whose machine learning algorithm would be trained on the data I had gathered, would predict the outcome of a user-generated petition. The game would employ the Naïve Bayes algorithm to predict whether a petition would be accepted or refused by the Poor’s Board – the council in charge of providing paupers with monetary help in 19th century Scotland.
Methodology
First, I had to outline the information I wanted to gather from the letters, i.e., which factors for petitioning I wanted to look for in the actual letters. After some reading on the topic, I outlined seven reasons for petitioning which I would then check as present or absent in each petition. The petitioning reasons I outlined were the following: illness (regarding the petitioner), having any (ill) children, being of old age, being widowed, having family that the petitioner themselves has to take care of, possession (or lack thereof) of land, and any help the petitioner might have received from neighbours or extended family. From there on, I manually checked each Tongue and Perth letter, and marked (in an Excel file) whether a petition had a mention of any of the factors. Most often, a single petition would mention several of these factors.
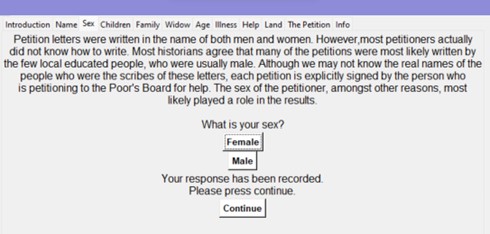
After I had finished working with gathering the data, I had to make the actual game. The game was programmed entirely in Python 3.10, as this allowed me access to multiple Python libraries. The main library I used for this project, however, was the Tkinter library. By using Python and the Tkinter library, I created a quiz whose answers would be recorded as a player navigates through a quiz, answering questions as if they were a petitioner writing a petition letter. As the player of the game answers the quiz questions, the answers are recorded as either ‘0’ or ‘1’ in a list, which, at the end of the game, is run through the machine learning algorithm. Once the quiz is completed, the machine learning algorithm predicts the outcome of the petition letter – whether it would be accepted or rejected by the Poor’s Board, based on the answers the user had chosen.
Interface
To give a general insight into how the game is played, I’ve provided some screenshots of its interface.
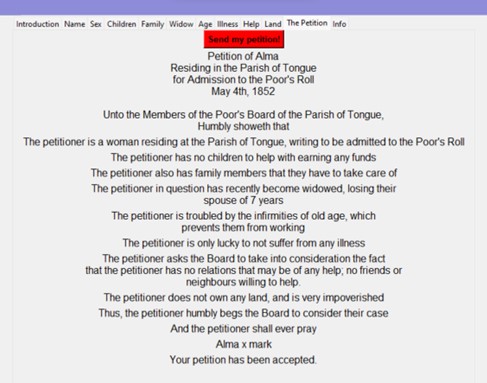
First, the player is greeted with an introduction page, which gives a general insight into the “rules” of the game – the player is invited to answer a series of questions as if they were a 19th century pauper explaining their living situation to the Poor’s Board. The aim of the game is not to “win” and be admitted to the Poor’s Roll; rather, it is an opportunity for people to learn about the factors that often played a role in the petitioning process. At the end of the quiz, the answers are reported back to the player in the format of a petition letter, of which they are also provided the result of.
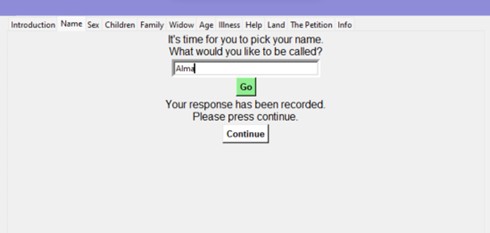
The quiz itself is very simple: the players are given a general outline of the history of Scottish petitioning for each factor that they answer a question for. This provides the player with some context as to why certain factors might be of importance when petitioning.
At the end of completing the quiz, the player is provided with a petition which has recorded every choice that the player has made while completing the quiz. This gives a general idea to an audience unfamiliar with Scottish petitions as to how a general petition might have looked like, both in its structure and the language it used.
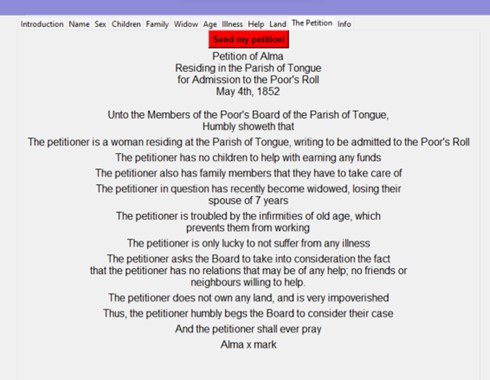
Once the quiz has been completed, the letter can be “sent off to the Poor’s Board” for evaluation. However, the way that the outcome of the letter is predicted is as follows: a list is created in Python, which is appended with each response that is given by the player. Then, the user-generated petition is compared to a test list of around 50 real petition letters, which have also been marked for each of the factors mentioned in the quiz. Afterwards, the letters are compared, using the Naive-Bayes classifier, and the outcome of the user-generated petition is predicted.
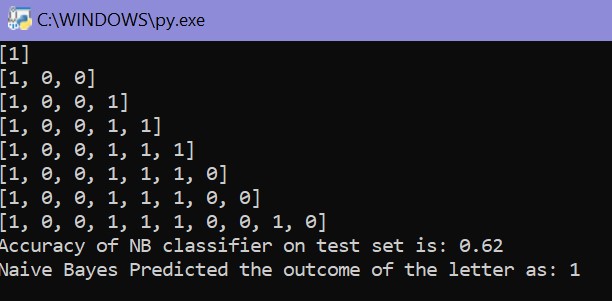
Once the machine learning algorithm has predicted the answer of the Poor’s Board, it is displayed at the bottom of the petition letter.
Outcome
While simple in its appearance (both due to time and my own coding knowledge limitations), my project was successful in completing the task of creating an interactive and informative way to engage with the history of petition writing in Scotland.
This is just one of the ways the data from the Scottish pauper petitions can be used. Further research could be done now in analysing linguistic data in particular, as, when I was creating my own project, the ScotPP corpus was not as complete as it is now.
I was able to find good information from your blog articles.